
De seguro habras oido sobre los operadores logicos de SQL SERVER; me refiero a los JOINS que realizamos al querer unir tablas. Pero… internamente SQL SERVER ejecuta operadores FISICOS que permitiran las combinaciones logicas de los JOINS. ¿Quieres saber de ello? Vamos.
Operadores Logicos
Como mencionamos anteriormente, cuando deseamos unir tablas podemos usar las combinaciones left join, right join, inner join y full join. Ademas de los operadores exclusive join, pero es otro tema.

- INNER JOIN: Devuelve registros que tienen valores coincidentes en ambas tablas.
- LEFT JOIN: Devuelve todos los registros de la tabla de la izquierda y los registros coincidentes de la tabla de la derecha.
- RIGHT JOIN: Devuelve todos los registros de la tabla de la derecha y los registros coincidentes de la tabla de la izquierda.
- FULL OUTER JOIN: Devuelve todos los registros cuando hay una coincidencia en la tabla izquierda o derecha
Operadores Fisicos
SQL Server usa las operaciones de combinación físicas para realizar las operaciones de combinación lógica. Esto es importante al momento de analizar los planes de ejecución que pueda tener nuestras consultas. Cabe mencionar que los operadores fisicos son utilizados por SQL SERVER de acuerdo a los datos que se tienen y a como se formulo la consulta.
Nested loops joins
Utiliza las entradas del join como tabla de entrada externa y tabla de entrada interna. Nested Join busca por cada dato de la columna de la tabla de entrada externa coincidencias en toda la tabla de entrada interna, la busqueda se hace por medio de la columna que se estan haciendo en la sentencia ON.
Imaginemos que la entrada de un join es pequeña (menor de 10 filas), y la otra entrada es bastante grande y está indexada en las columnas en las que se hace ON, SQL Server preferira usar un Nested join de índices como la operación de combinación más rápida, debido a que requieren menos E/S y menos comparaciones.
Veamos un ejemplo usando Nested Loops Joins. Usaremos Northwind.
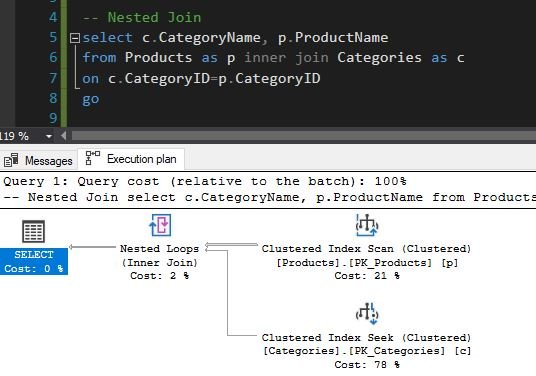
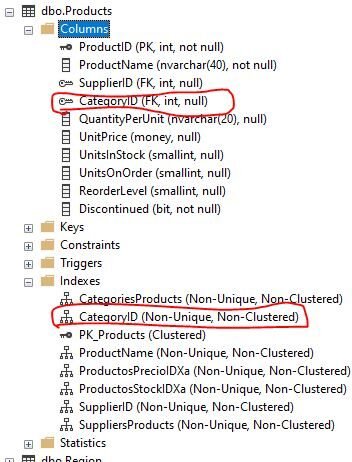
Se puede ver que en la Fig 3 la tabla Products tiene la columna CategoryId como un indice. Recuerda que cuando creas un foreign key NO se crea automaticamente un indice, lo que si sucede cuando declaras el Primary Key. En la Fig 2 podemos ver que SQL Server decidio hacer un Nested Loops Join probablemente debido al indice de CategoryID que encontro en la tabla Products y a las pocas filas que tienen las tablas Category y Products (8 y 78).
Nested Loops Joins es efectiva SI la entrada externa es pequeña y la entrada interna está preindexada y es grande. En muchas transacciones pequeñas, conjunto de filas afectadas, los Nested Loops Joins de índice son un tanto superiores a los Merge Join y a los Hash Join. En consultas grandes, sin embargo, las combinaciones de Nested Loops Joins no suelen ser la opción óptima.
Cabe mencionar que Nested Loops Joins tambien se aparece en el plan de ejecucion de SQL SERVER cuando occurre un Key Lookup, y para que esto ocurra no es necesario establecer la palabra reservada join en tu query. 🤔
Merge Joins
Requiere que ambas entradas donde se estan haciendo el join esten ordenadas por las columnas que están definidas por las cláusulas de igualdad (ON). El optimizador de consultas generalmente escanea un índice, si existe uno en el conjunto de columnas adecuado. En casos excepcionales, puede haber varias cláusulas de igualdad, pero las columnas de combinación se toman solo de algunas de las cláusulas de igualdad disponibles. Como ambas entradas estan ordendas la busqueda sera más rapida ya que no se tendra que recorrer toda la entrada, por ejemplo: si se buscare el dato 3 en la otra entrada ( 1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 4, ,4, 5, 5, 6, 7, 7, 8….. ). La busqueda se detendria hasta encontrar la ultima coincidencia (3) ahorrando asi tiempo al no recorrer toda la entrada.
Veamos un ejemplo usando Merge Joins. Usaremos Northwind.

En la Fig 4 vemos que SQL SERVER opto por usar Merge Join probablemente porque el tamaño de las entradas no son pequeñas y que a su vez las columnas (las declaradas en el ON ) estan ordenadas ya que CustomerId es un indice declarado en la tabla Orders.
Merge join en sí mismo es muy rápido, pero resulta costoso si las entradas no estan ordenadas, puesto que primero ordenara las entradas antes de usar el Merge Join. Sin embargo, si el volumen de datos es grande y los datos se pueden obtener preordenados por los índices, Merge Joins suele ser el algoritmo de combinación más rápido disponible.
Hash Match Joins
Se considera dos entradas: la entrada de compilación y la entrada de sonda . El optimizador de consultas asigna el rol de entrada de compilación a la de menor tamaño.
Los Hash Join en memoria crean una tabla hash en memoria despues de haber calculado la entrada de compilación. Cada fila se inserta en la tabla hash según el valor hash calculado para la clave hash. A continuacion le sigue la fase de sondeo. Donde toda la entrada de sonda se escanea o calcula una fila a la vez, y para cada fila de la sonda, se calcula el valor de la clave hash para compararlas con los del cubo hash correspondiente y se producen las coincidencias. Existen tres tipos de hash join (in memory, Grace y Recursive ), pero en resumen todas crean una tabla hash lo que toma su tiempo.
Veamos un ejemplo usando Hash Match Joins. Usaremos Northwind.

En la Fig 5 podemos ver que se uso el Hash Match Join probablemente porque los indices habidos no eran suficientes para mostrar la informacion solicitada y por el tamaño de las entradas. Podriamos pensar en redefinir el indice como una solución si las columnas solicitadas son necesarias recurrentemente.
En resumen al ver en los planes de ejecución los operadores fisicos mencionados anteriormente tendremos una idea de las caracteristicas de los datos que se estan uniendo y de la calidad de nuestros indices, esto nos ayudara a tomar decisiones para optimizar nuestras consultas. Recuerda SQL SERVER toma la desicion de cual operador fisico usar, esto depende de los datos que tenemos y la query formada, aunque nosotros podriamos forzar en nuestros queries a que use cierto tipo de operador fisico, pero habria que analizar si eso retornaria los datos más rapido.